Improving stability and fixing issues on searchmysite.net
Introduction
In my last major post, searchmysite.net update: Seeding and scaling from 25 Sept 2020, I concluded “I’ll ease off on enhancements, and try to focus on adoption for a while”. So how has that gone? Well, I had a nice burst of activity between 16 and 19 Oct, with 215 sites submitted in 4 days, which was great and led to some really useful feedback, including the first site to use the searchmysite.net API to power their search page. However, the higher levels of usage did expose some issues, which I’ll summarise here.
Improving stability
On 19 Oct I had the first (and it has to be said so far the only) outage of searchmysite.net. The good news is that the monitoring and alerting triggered. The bad news is that it happened just after I went to bed and I put my phone on Do Not Disturb overnight, so I didn’t find out until the morning. After restoring the service (the usual IT solution - switch it off and on again), I undertook a post-mortem to try to prevent a repeat.
It turned out that the system had run out of memory trying to index a ginormous .cbr file1, which starved all the other parts of the system of resources and brought them down in a non-recoverable way. Clearly a problem with indexing one file shouldn’t have such catastrophic consequences for the entire system, so it called for a lot of changes.
Quick fixes
The immediate changes were to:
- Add .cbr files to the “do not index” list.
- Put a limit on the size of file that can be indexed, by setting DOWNLOAD_MAXSIZE which stops downloading a file after a set number of bytes. I’d left that value at the default, which turned out to be 1Gb. If I’d know it was that high I’d have changed it sooner, given I currently have the search engine, database and web server all running on a machine with 4Gb. I’ve set the limit to 1Mb for now.
- Limit indexing to 20 concurrent sites in one twisted reactor.
- Add a “restart: always” to the docker compose file, to try and get services to recover if there is a failure.
Unfortunately it doesn’t seem like it is possible to protect the memory usage of each container - the deploy key (with resources/limits/memory subkey) only works in docker compose version 2 (I’m using 3), or in version 3 if using swarm (which I’m not).
AWS memory monitoring
I also realised that while the default AWS monitoring (and hence alerting options) covers CPU, disk and network, it does not include memory. The official explanation for this is that CPU, disk and network metrics can be collected at the hypervisor level, but memory metrics have to be collected at the OS level. The solution is to install the CloudWatch Agent on the container OS and ship the logs to CloudWatch. So I’ve done this, and now have some nice memory monitoring, and an alert for when the memory usage goes above a certain threshold.
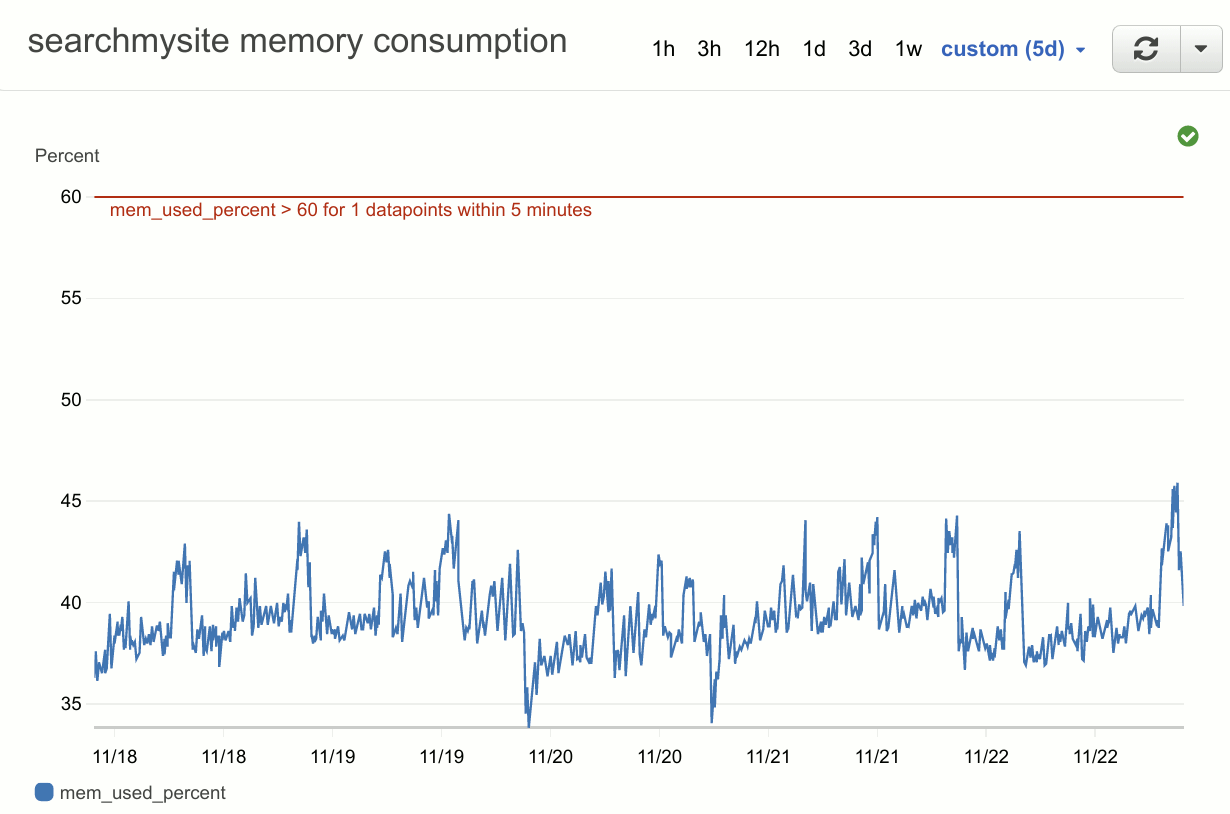
On the graph above, the peaks generally correspond to indexing jobs, and the troughs are when the service is restarted as part of a deployment.
Moving SSL termination from Apache httpd to an nginx reverse proxy
Longer term, I will need to look at splitting out the components onto different servers, particularly the indexing server, potentially also the web server. I should also think about having some redundancy, initially for the indexing server and the web servers, so if one fails the service can continue. That does however risk increasing the running costs, and I don’t want to get to the point where it becomes too expensive a service to continue self-funding.
I have tested having multiple indexing servers running concurrently, and that works fine, but given how memory hungry it is, I’m not sure there’ll be much advantage to running up multiple instances on the same server.
One infrastructure change I have made though, which will make it easer to have multiple web servers, is to move the SSL termination from Apache httpd (inside docker), to an nginx reverse proxy (on the docker host). That has the added benefit of simplifying the development environment too - now the development and production Apache httpd config is exactly the same.
Improving stability - conclusion
With all of these changes the system will be lot more stable now. Although it would still benefit from additional expenditure on redundancy, it should be good enough to not have to worry too much overnight.
Fixing issues
Along with the increase in usage came a few bug reports, and a few issues I managed to spot without (hopefully) anyone noticing them. Needless to say, the bug reports are very much appreciated, because they help get them resolved before too many other people encounter them. I won’t go into full details of all the issues, but will pick out four of interest.
Verified Add goes to the logon page
A user reported being unable to use the Verified Add, because it took them to the logon page. I couldn’t see any reason why that would be the case at first, but after tracing through their steps, it turns out they’d clicked Manage Site before Verified Add (which isn’t an unreasonable thing to do if you’re looking around trying to decide if you want to add your site). This set up the session cookie with an incorrect redirect_uri. Once identified the fix was relatively simple, but it is a good example of an unusual issue which is hard to avoid or detect while developing, and is one of the reasons it is good to ramp up usage with real users in a controlled manner so it can be more “battle tested” before reaching a wider audience.
Some sites not getting indexed
There was a slight mismatch between the number of sites submitted, and the number indexed. It turns out that 10 sites had a robots.txt with the following:
User-agent: *
Disallow: /
This meant that the indexer, which respects the robots.txt, didn’t index those sites. The short term fix was to (manually) move those sites to the “do not index” list, so if anyone resubmits to check on their status they’ll see the message ‘… has previously been submitted but … Access blocked by robots.txt’. I also improved logging to flag this scenario, and added a Contact form with that as one of the query options. Longer term, there are several other potential changes I’ve logged to better handle scenarios like this.
Misleading “Ad” icon
Someone asked if the site was funded by advertising, because they’d seen an Ad icon in the results. This came as a bit of a shock given everything I’ve previously written about how most of the main problems with the internet can be traced back to the effects of the advertising-based funding model, and how the motiviation for this project was to show that a search engine can exist and be sustained without any advertising. But it was also quite understandable, given the icon I’d used to indicate that a page in the results contains adverts was pretty much the same as the icon other search engines used to indicate that a result is an actual advert. Another example of why it is great to get feedback from users. Needless to say I fixed that one pretty quickly, ressurrecting the old design I mentioned in the first post searchmysite.net: Building a simple search for non-commercial websites, i.e. a “Contains Adverts” icon in the style of the Parental Advisory warning:

Domain Control Validation process not completing for some users
A user reported that they were unable to complete the Domain Control Validation process for their site. It turns out that they were using firebase with cleanurls configured, and this sends a 301 response for a request for a <validation_key>.html to redirect to a file called simply <validation_key>, and the code didn’t follow redirects. Workaround was to use the meta tag approach. But while looking into this I noticed a larger number of incomplete submissions than I’d have expected. Recreating them on dev, I was finding that many of them were failing to validate, but looking at the code I really couldn’t understand why. I’m using https://github.com/rs/domcheck for this functionality. To cut a long story short, it turns out that despite being last modified in 2017, the domcheck package on pip didn’t have the latest code I had been looking at, but an earlier version that was missing the crucial bug fix at https://github.com/rs/domcheck/commit/b0d1a1427e22805cea2cedc49039facbb5e516e4. Big lesson there is to check the status of the builds, and confirm the contents of the package.
Fixing issues - conclusion
With all of these fixes, I think the application is much more ready for higher usage levels now. To be honest I’m kind-of glad the usage has been low enough to allow some breathing space for fixes. Remember this is just an evenings and weekends side-project at the moment. But that said, there may still be a few as yet undiscovered edge cases. When I’ve got the documentation, testing etc. ready for open sourcing, I’ll also open up the issue log, which of course will will mean greater transparency without the need for posts such as this.
-
I didn’t know what a .cbr file was until then, but now I know it is a Comic Book aRchive file. ↩︎