An update on the automated SEO searches issue
This post is to provide an update on the automated SEO searches issue described in my last post Almost all searches on my independent search engine are now from SEO spam bots. It references the discussion on Hacker News (HN) from Mon 16 May.
Traffic and system performance and stability
In terms of traffic, there were 18,034 visitors to blog.searchmysite.net on Mon 16 May and 2,699 visitors to searchmysite.net, pretty much all of which came as a result of the HN post:
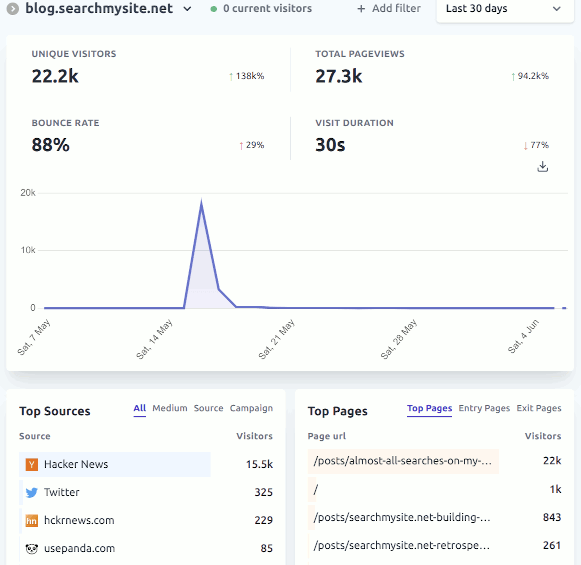
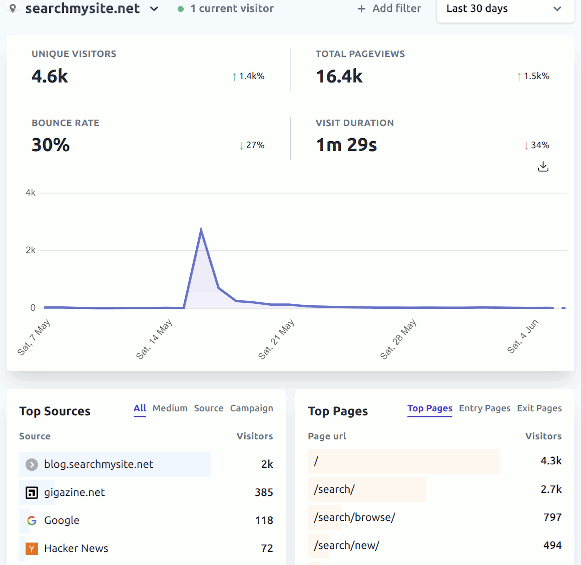
In terms of performance and stability, the 2 CPU 4Gb RAM machine handled the traffic without any issues.
Although the extra traffic was still dwarfed by the automated SEO searches, which were still coming in thick and fast at the time:
| Day | Real searches | Total searches |
|---|---|---|
| Mon 16 May 2022 | 1,722 | 143,796 |
| Tue 17 May 2022 | 405 | 166,742 |
| Wed 18 May 2022 | 141 | 71,522 |
| Thu 19 May 2022 | 94 | 39,255 |
| Fri 20 May 2022 | 53 | 21,535 |
| Sat 21 May 2022 | 58 | 14,130 |
| Sun 22 May 2022 | 38 | 15,931 |
| Mon 23 May 2022 | 27 | 16,303 |
| Tue 24 May 2022 | 19 | 11,115 |
| Wed 25 May 2022 | 9 | 6,541 |
| Thu 26 May 2022 | 10 | 5,858 |
| Fri 27 May 2022 | 12 | 2,282 |
| Sat 28 May 2022 | 7 | 3,281 |
| Sun 29 May 2022 | 9 | 4,609 |
| Mon 30 May 2022 | 8 | 2,566 |
| Tue 31 May 2022 | 12 | 3,145 |
| Wed 01 Jun 2022 | 6 | 3,887 |
| Thu 02 Jun 2022 | 9 | 7,170 |
| Fri 03 Jun 2022 | 5 | 9,119 |
| Sat 04 Jun 2022 | 3 | 4,259 |
| Sun 05 Jun 2022 | 4 | 3,283 |
| Mon 06 Jun 2022 | 3 | 3,959 |
| Tue 07 Jun 2022 | 3 | 3,074 |
| Wed 08 Jun 2022 | 1 | 3,219 |
Most of the automated searches were blocked at the reverse proxy level so placed minimal load on the system, but still, I think the system handled the load well. Not having user tracking and session management does help with scalability.
There was one minor issue 2 days later (i.e. on Wed 18 May), where the unexpectedly large log files filled up all the available disk space. However, the way the partitions are set up this only impacted the analytics.
Ideas on how to tackle the automated SEO searches issue
The core issue is the vast number of automated SEO searches, i.e. searches for “scraping footprints” combined with the SEO search terms to get list of URLs to target, which are run on “SEO proxy farms” to be difficult to trace and block. This is a problem which is very specific to search engines, i.e. not a particular problem anyone is likely to have encountered if they haven’t run a search engine.
There were lots of proposed solutions, most of which would have required code-level changes, and so would have put additional load on the servers. The only proposed solution which wouldn’t place load on the servers was to use Cloudflare.
I experimented with a number of options in Cloudflare, e.g. a Web Application Firewall (WAF) rule to block Known Bots, but these didn’t have any apparent affect, e.g. because the bots were unknown bots rather than known bots. After a few days I settled on the following Cloudflare configuration:
- A WAF rule to block requests to /search above a certain threat score. At a threat score of 80 blocked around 0.1% of requests, and lowering the threat score to 40 blocked around 4% of requests, so it did help a little.
- Switched Bot Fight Mode on. This includes JavaScript Detections, which I really thought would work because it injects some JavaScript onto every page and rejects requests which don’t execute the JavaScript, similar to how the analytics solution avoids counting bots. There aren’t any stats on how many requests have been blocked by this, but initial informal scanning of the logs suggested it wasn’t doing much, and switching it off didn’t seem to affect usage much either.
So Cloudflare wasn’t the “silver bullet” I was hoping for.
The initial solution, i.e. blocking requests with no referrers at the Reverse Proxy (RP), had some unfortunate side effects, such as breaking the OpenSearch browser integration (e.g. Firefox search bar) and preventing direct links to search results. So I revised the RP config, and now block requests with no referrer and where the query is above a certain length. The theory is that this will block the longer ‘“Powered by <system>” <search term>’ type of requests while still allowing shorter direct links without referrers, e.g. /search/?q=domain:michael-lewis.com. Still not a great solution though.
Anyway, there’s a bit more detail on what changes were made in https://github.com/searchmysite/searchmysite.net/issues/55.
The final point to note is that it seems like the problem is starting to fade away, as the stats above suggest. It is possible that this is due to the reverse proxy blocking most requests. Anyway, the impression I get is that SEO spam is a bit like an infectious disease. It comes in waves, but even when a big wave dies back, it never completely goes away, and might of course come back again in a new form. So I’m starting to wonder if the “solution” is to learn to live with it.
What is the purpose of searchmysite.net and why should I use it?
There were a surprising amount of people on HN who saw a search box, assumed it must be a Google replacement (because isn’t that what all search boxes are?), and complained that it was a terrible failure when they found out it wasn’t.
searchmysite.net has always been intended to be a niche or boutique search, focussed on searching the “indieweb” or “small web” or “digital gardens” or whatever you want to call that sort of non-commercial content. It has never aimed to search the whole internet, not just because of the amount of junk on it, but also quite simply because it would cost way too much money for a bootstrapped side project to index the whole internet (I even had to stop indexing wikipedia to keep costs under control).
That then threw up two further issues:
-
Many people had no idea what the non-commercial internet is. That is not really something for searchmysite.net to educate people about, but I guess you can side-step the issue by saying that if you don’t know what it is you probably aren’t going to want to search it.
-
Even for people who know what the non-commercial internet is, the question is - why should I search it, what benefit does using searchmysite.net give me? That is a very important question, and one that I think is answered by some user feedback: “When I search [full-internet search engine] for people’s personal experiences or deep-dives into topics, I usually get bombarded by marketing websites or company blogs that repeat the same things ad nauseum. The manual filtering offered by Search My Site has been incredibly helpful to get past that. [98% of my searches still use a full-internet search engine, but] For the remaining 2%, things like what people put into their Anki decks or experiences using borg backup software, I’ll open up SMS … Once I’ve found the articles I need, I’ll normally jump around the rest of the website and add it to my RSS feeds”.
I’ve amended the explanatory text on the main home page, and also on the About searchmysite.net page, to hopefully make it clearer what searchmysite.net is and isn’t, and when you might want to use it.
Unresolved challenges for searchmysite.net
Moderation is difficult to scale
There were 246 site submissions on 16 May 2022, 66 on 17 May, and 20 on 18 May. Each needed to be individually reviewed prior to indexing, which took a fair bit of time. The unexpectedly high effort required to moderate has been flagged as an issue before, although this is not necessarily an unsolvable issue - support has been added for multiple moderators, so I’d just need some volunteers to help.
Moderation is of limited effectiveness
This is a bit more of a tricky one. The current moderation process involves reviewing the site on initial submission, and then re-reviewing it every year.
Unfortunately, users spotted sites which had clearly become infected with spam. One was open source and had been hijacked after the initial approval, and the other still had a legitimate looking home page and blog but a complete spam subdomain which I hadn’t spotted (and which could quite possibly have been the victim of a subdomain takeover attack by spammer). Both were delisted immediately.
Another user claimed to have found pro-terrorism sites. I couldn’t find any further details, but it is possible that these lurk under legitimate looking home pages and blogs.
This does lead to the conclusion that:
- Sites can change between the initial approval, and the re-approval a year later.
- Sites can have legitimate looking home page and blog entries, which mask more malicious content within.
Not completly sure what the solution here is. Perhaps a report button on the search results page or something like that, although as per the point above the moderation as it is does have a scalability issue.
Most searches are still automated SEO searches
As the stats above show, the number of real searches is falling back to earlier levels, so we’re heading towards the original concern - that almost all searches are still automated SEO searches. It isn’t the objective of searchmysite.net to be primarily of benefit to “SEO practitioners”.
No mention of the search as a service
One interesting point is that, in all the discussion about the pros and cons of searchmysite.net, there was no mention of its (quite possibly unique) funding model.
Most search startups (in fact most startups) start out as being free, but when they run out of funding, they either fail, or switch to advertising. There are some search startups proposing a subscription model, and of course some relying on donations, but those haven’t yet (for search) proved to be sustainable models. searchmysite.net is, as far as I know, the only search engine which aims to pay its running costs via its search as a service. It still hasn’t quite reached the self-sustaining level yet, but after I switched to cheaper hosting and stopped indexing wikipedia to cut costs earlier in the year, it is closer to that point.
Perhaps I need to promote the search as a service more.
There are real people on the internet, it isn’t just bots
A final point worth mentioning is that, in addition to the public comments, I got a number of personal messages, which is really great and much appreciated. I think I have replied to all personally now. But it just goes to show that the internet isn’t all bots.