searchmysite.net retrospective and future plans
Introduction
It has been around 1.5 years since I launched searchmysite.net as a side-project to try and address the problems with the current commercial internet search offerings, and I reckon I’ve now spent around 650 hours working on it1. The 2021 year end seems a good opportunity for a retrospective of what has gone well, what has gone neither well nor not so well, and what has not gone so well. And based on that, some thoughts on where it should go in 2022. Given the nature of the project, this will be an open and honest account rather than a Silicon Valley style “fake it ’til you make it” piece.
What went well
Good feedback about useful search results
For a search engine, useful search results are really what matter most, and I’m pleased to say I have received some good feedback in 2021:
- “I tried it just once, with ‘startup ideas’ and I can see how it gives more useful results than google for this simple phrase.”
- “I searched for ‘self tracking’ which brought me to a site by Peter Stuifzand where I encountered the expression ‘manual until it hurts’ which I like.”
Excellent stability
As per Progress update Q1 & Q2 2021, there were a couple of instances where indexing got stuck due to running out of disk space in the first half of 2021, but searching remained operational during that time, and alerts were set up to prevent future such issues. There haven’t been any stability related issues in the second half of 2021.
What went neither well nor not so well
Usage levels didn’t increase through 2021, but didn’t decline
The number of page views over the past 15 months hasn’t trended upward, but hasn’t trended downwards either:
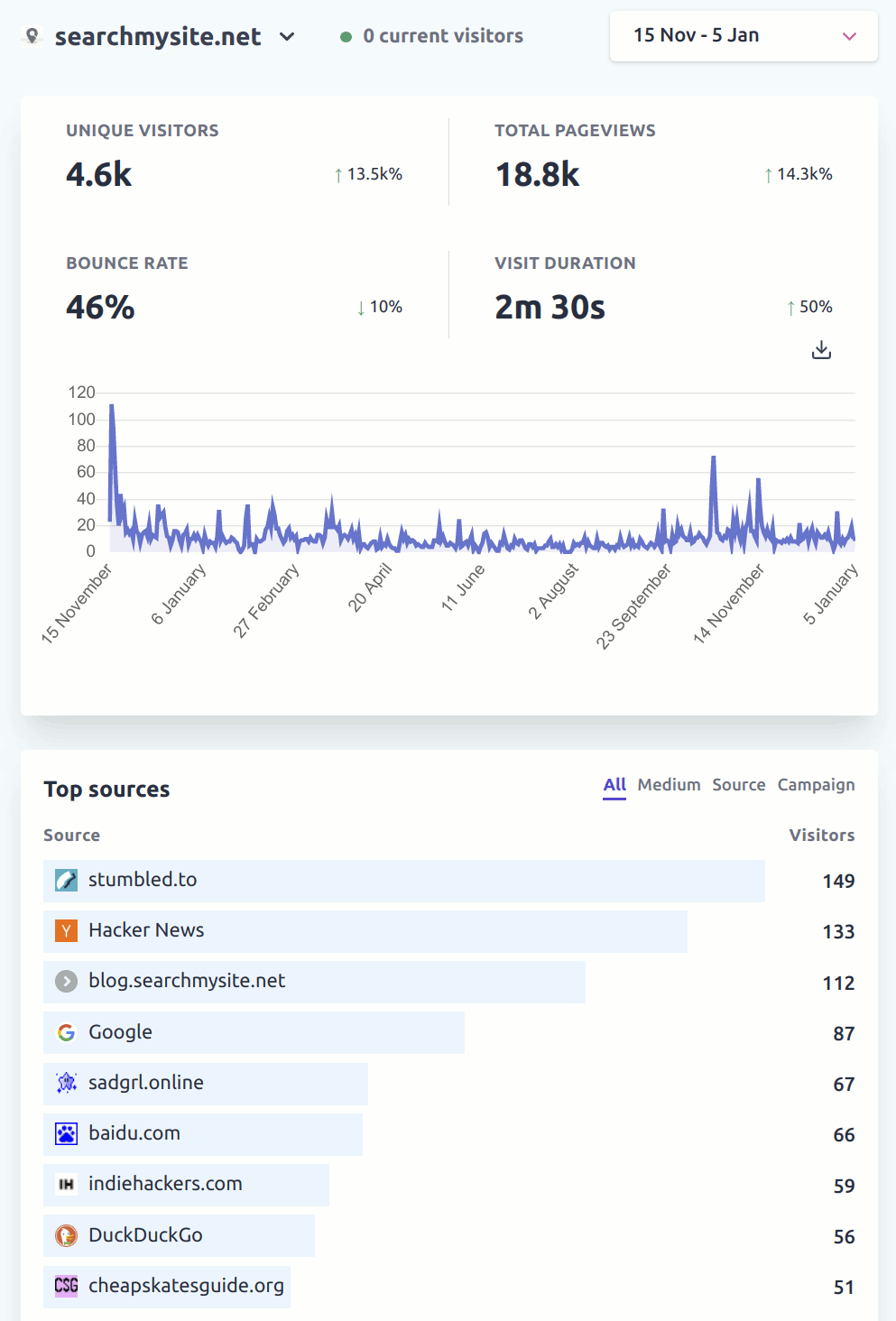
Some people didn’t like the addition of wikipedia content, but some people did like it
The jury is still out on whether indexing wikipedia was a good idea or not. It was a useful learning exercise though, and showed the system can scale, plus opened up the possibility of implementing additional custom indexing processes for other sites.
Worst case I can simply remove the wikipedia content.
Seven paid listings in 2021 (approx $108 annual revenue)
An annual revenue of £80.15 (after fees), or approx $108, doesn’t sound very much, especially given the running costs detailed below. However, it does provide some validation, and it could be worse, plus it is a really good feeling to see people paying to use your project, so many thanks for those who went to the time and expense to complete the payment process - it is genuinely appreciated.
What didn’t go so well
Escalating running costs (now nearly $1000 per year)
The bills so far have been:
| Month | Cost |
|---|---|
| July 2020 | $9.04 |
| August 2020 | $20.47 |
| September 2020 | $28.95 |
| October 2020 | $41.09 |
| November 2020 | $44.64 |
| December 2020 | $47.13 |
| January 2021 | $47.35 |
| February 2021 | $44.43 |
| March 2021 | $47.94 |
| April 2021 | $47.70 |
| May 2021 | $49.11 |
| June 2021 | $48.54 |
| July 2021 | $49.54 |
| August 2021 | $53.78 |
| September 2021 | $53.22 |
| October 2021 | $65.47 |
| November 2021 | $75.85 |
| December 2021 | $77.00 |
The big jump from October 2021 is a result of adding approx 6.5 million documents by indexing wikipedia.
At $77 per month, it will cost $924 per year to maintain, although if costs continue to escalate it is likely to exceed $1000 per year. Now I’m sure I could change hosting provider to significantly reduce costs, but it is not currently looking hugely likely that it’ll be able to become self-sustaining in 2022.
Blog entries not being read (sometimes 0 page views for over a week)
As the analytics show, this blog is very rarely visited:
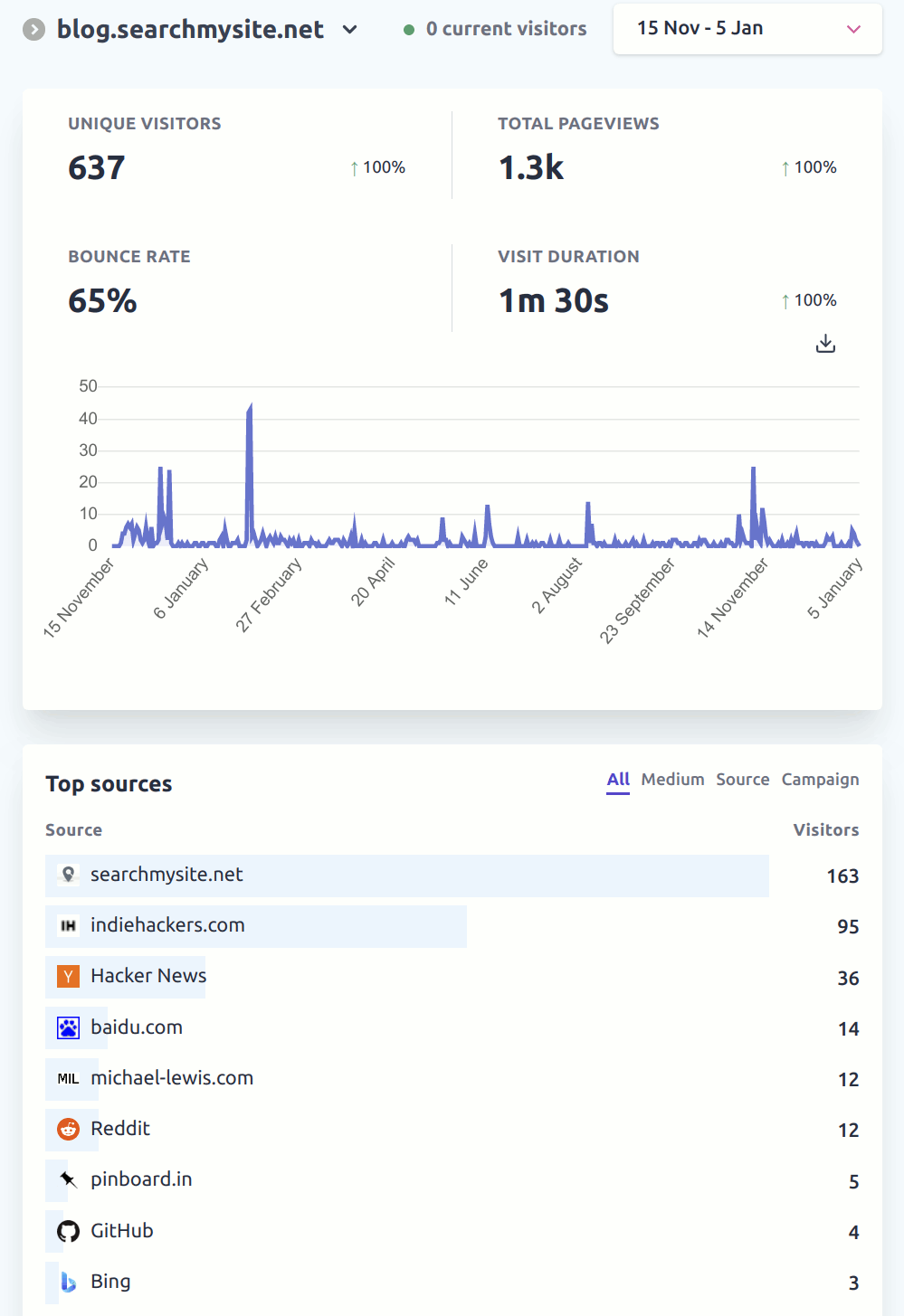
There have even been 3 weeks with 0 page views during the entire week. That is quite disappointing to be honest.
Part of the issue appears to be that the major search engines aren’t sending any traffic to the blog for some reason, despite my having spent time submitting to the search engines and performing some Search Engine Optimisation (some details in Progress update Q1 & Q2 2021). This is especially odd given that the blog contains original content rather than SEO-spam, and there are some useful non-project-specific posts covering topics such as relevancy tuning and how to index Wikipedia. If only there was an alternative search engine where people could find original and useful content…
Search as a service not being used much
I’ve described the public search as the “loss leader”, with the search as a service being what pays for the running costs (rather than adverts or the sale of personal data or anything like that).
But unfortunately the search as a service isn’t being used much. Of the key search as a service features:
- Nine users have used the custom exclusions functionality to configure what is indexed.
- Four users did use the indexing on demand in 2021, although one is unfortunately one of the sites where indexing is currently blocked by Cloudflare.
- One user did use the API to drive the search box on their personal site, but that was one of the large number of sites which went offline in 2021.
Not entirely sure why it hasn’t been more used to be honest. There do seem to be a lot of successful search as a service offerings, e.g. Algolia which has attracted $334.2M in Venture Capital funding, so there is a market for search as a service. Maybe it is simply that many of the target audience for searchmysite.net, i.e. personal and independent site owners, don’t want or need a search as a service.
Unexpectedly high effort required to moderate
There were several weeks towards the end of 2021 when all my project time was spent on site moderation and the annual review of 605 expired Quick Add sites and 66 expired Verified Add sites.
So I’m not sure how sustainable the curated approach is for a solo side-project. This would be a little more manageable if there was more than one moderator, and support for this has been added via issue #20.
Submissions are primarily people’s own sites rather than interesting sites they’ve found
I had hoped that people would submit interesting sites they’d found via Quick Add and their own sites via Verified Add. Kind-of like a search engine equivalent of stumbled.to (which BTW has been the biggest source of traffic to searchmysite.net over the past year as shown in the analytics above). But what seems to be happening is that people are simply submitting their own sites via Quick Add, and not using Verified Add.
This means the collection of interesting sites isn’t growing as quickly as it could, and of course there aren’t enough listing fees to pay the running costs.
I changed the call-to-action on the home page from “Tip: try searching for hobbies or interests” to “Help improve it by submitting your favourite sites via Quick Add or your own site via Verified Add (both available via Add Site)” to try to help, but that doesn’t seem to have had any effect.
Not managed to build a community of people interested in building a better internet search
When I launched the project I had high hopes of building a community of people interested in building a better internet search. As per the two points above, that would include:
- people submitting personal and independent sites they found interesting, to improve the scope of the search
- people interested in helping moderate, for a community-based approach to content curation
In addition, by open sourcing searchmysite.net, I hoped the community would grow to include:
- people interested in helping enhance the code, including improving the search relevancy tuning, to make a better search
- people setting up their own instances to search other parts of the internet, with grand ideas (covered in more detail in open sourcing searchmysite.net) of a federated search interface on top of all of these instances
Unfortunately that doesn’t seem to have happened.
I have found quite a few people working on similar projects though, and still have a hope that somehow efforts could be combined, or even simply that knowledge could be shared e.g. via a Discord server for independent search engine developers or something like that.
Conclusion
In my first post in July 2020 I said there was growing evidence of people becoming dissatisfied with the current commercial internet search offerings, and provided a number of references to support this claim. I still believe this to be the case, and if anything it seems dissatisfaction has actually grown through 20212.
I also still believe that the main issue is SEO-spam, and that the advertising-driven search model is what incentivises SEO-spam, so an improved alternative should use another funding model. I also still think that people paying for a search as a service isn’t unreasonable.
All that said, given all the “What didn’t go so well” points above, it is hard not to think that searchmysite.net, at least in its current form, might not be the solution to the problems with the current internet search offerings, even if some of the ideas it introduced, e.g. open sourcing the relevancy tuning and downranking results containing adverts, might still end up being adopted by other solutions.
So the plan for 2022 is to spend less time on the project, especially on blog entries, and look to move to a cheaper hosting provider around mid year. I will of course continue maintenance activities, e.g. checking the new submissions on a daily basis and approving/rejecting accordingly, checking and responding to emails, fixing any issues if necessary, etc. I will also review again at the end of 2022, and see how things have gone.
-
In searchmysite.net: The delicate matter of the bill I estimated that I’d spent around 350 hours on the project by January 2020. In the year since then, I’ve mostly been working on it in the 2 hours a day I’ve saved by not commuting, although did restart commuting some days a week towards the end of the year. At a rough guess, I’d say I’ve averaged around 6 hours a week working on the project in 2021, i.e. a further 300 hours to add to the 350 hours to January 2020. ↩︎
-
e.g. posts such as A search engine that favors text-heavy sites and punishes modern web design and Google no longer producing high quality search results in significant categories which were among the highest-voted submissions on Hacker News in the whole of 2021. ↩︎