searchmysite.net now with added Wikipedia goodness
So I’ve finally managed to index Wikipedia, or at least the 6,392,807 English language pages.
Some of the benefits this brings to searchmysite.net:
- It turns it into a much more useful search engine for day-to-day usage. Many of my internet searches in the past have simply ended with clicks to Wikipedia, so now when I’m performing that sort of search I can use searchmysite.net to get the Wikipedia link and see if there are any other personal or independent sites which have anything interesting to say on the topic. It could still benefit from users submitting more good quality personal and independent websites for indexing1, and some other changes such as extending its relevancy tuning, but it is definitely showing promise.
- It shows that the system can handle nearly 6,500,000 documents, even on a single relatively low spec server. As an aside, this is nearly a quarter of the size of the first Google index in 19982.
- The mechanism for allowing the indexing process to differ on a site-by-site basis opens up the possibility of implementing additional custom indexing processes for other sites. Maybe, being open source, people could even contribute their own in future.
BTW, if someone wants to try out the Wikipedia import, they can simply spin up a searchmysite instance using the 8 commands listed in the README.md, and then run import.sh via docker exec -it src_indexing_1 /usr/src/app/bulkimport/wikipedia/import.sh.
This post has some more technical information on the indexing of Wikipedia for searchmysite.net.
How searchmysite.net indexes Wikipedia
Choosing a Wikipedia dump
Spidering such a large amount of content, with sensible rate capping, isn’t really viable. Indeed the page at https://en.wikipedia.org/wiki/Wikipedia:Database_download explicitly states “Please do not use a web crawler to download large numbers of articles.”
Fortunately there are a number of data dumps available at https://dumps.wikimedia.org/. I’ve used the Cirrussearch dump. This is an extract of the Elasticsearch index, which is in a similar format to that used by Apache Solr (BTW Wikipedia used to use Solr). You can actually see the Cirrussearch format for an individual page by adding ?action=cirrusDump to the URL, e.g. https://en.wikipedia.org/wiki/Apache_Solr?action=cirrusDump.
The Cirrussearch dump appears to be updated approximately once a week, in line with most of the other exports.
Reformatting the Cirrussearch dump
There are quite a few fields there which don’t have an equivalent in the searchmysite.net schema, e.g. template, and the searchmysite.net schema has some key differences, e.g. I need to convert the list of external_link to indexed_inlinks, indexed_inlink_domains and indexed_inlink_domains_count for the PageRank style algorithm, so some processing and reformatting is required. But the Cirrussearch dump looked like it would be one of the easiest to process. Alternatives include the Wikidata dump (which would require a lot of processing) or the OpenZim extract.
Unfortunately there are some potenitally useful fields I don’t really have a place for at the moment, e.g. popularity_score, so these are just lost at the moment.
Customisable indexing type
Previously searchmysite.net simply spidered every site. I’ve now added an indexing_type field to tblDomains. This currently just allows ‘spider/default’ and ‘bulkimport/wikipedia’, but could be extended, most likely within the spider and bulkimport subcategories. I’ve also moved much of the processing code, such as the code which inverts the list of outgoing links to determine the incoming links for a page, to some common utilities. This will make it much easier to add further custom indexing types in future, if there is interest in doing so.
Scheduling
The index.sh does check what Wikipedia export was used for the last import and whether there is a new one available, and only performs the import if there is one, so it is automated in that sense.
However, it isn’t currently scheduled. This is because I had planned on temporarily increasing the storage, running the import, and decreasing the storage, to avoid paying for the additional storage when not in use. However, it turns out that you cannot decrease storage (more on that in the Cost section below).
Wikipedia index loading statistics
System requirements (storage, CPU and memory) during Wikipedia import
The compressed Wikipedia download is around 32.5Gb, and uncompressed it is around 120Gb. The data load therefore needs an extra 153Gb storage while running.
After loading into Solr, Solr’s index increased in size by around 40.75Gb, which is not bad considering the original compressed file was 32.5Gb.
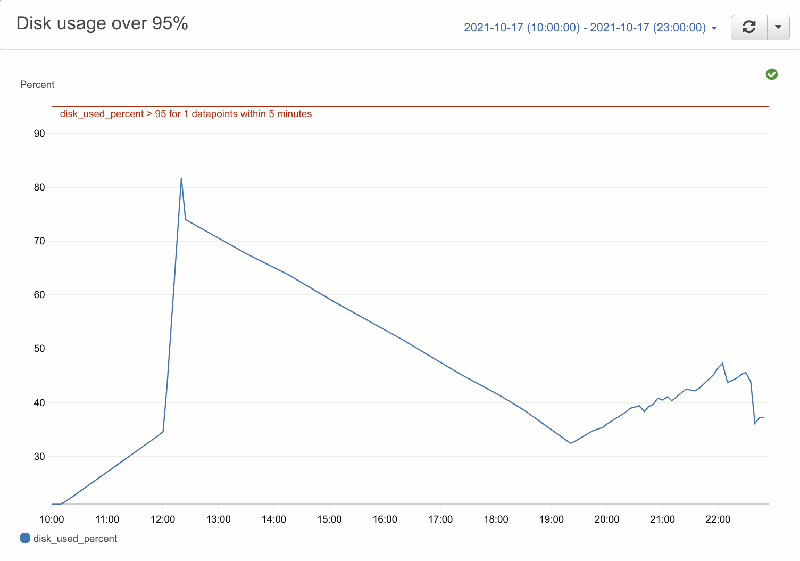
Here’s how the storage usage varied during the 5 step import:
- Step 2 Download: Increased from 21% of 250Gb (52.5Gb) to 34% (85Gb) during download, i.e. download was 32.5Gb.
- Step 3 Uncompress: Peaked at 82% of 250Gb (205Gb) after uncompress and split then down to 74% (185Gb) after original file deleted.
- Step 4 Reformat: Went from 74% of 250Gb (185Gb) to 32.5% (81.25Gb).
- Step 5 Load: Started climbing from 32.5% to a peak of 47.3% (118.25Gb), before settling on 37.3% (93.25Gb).
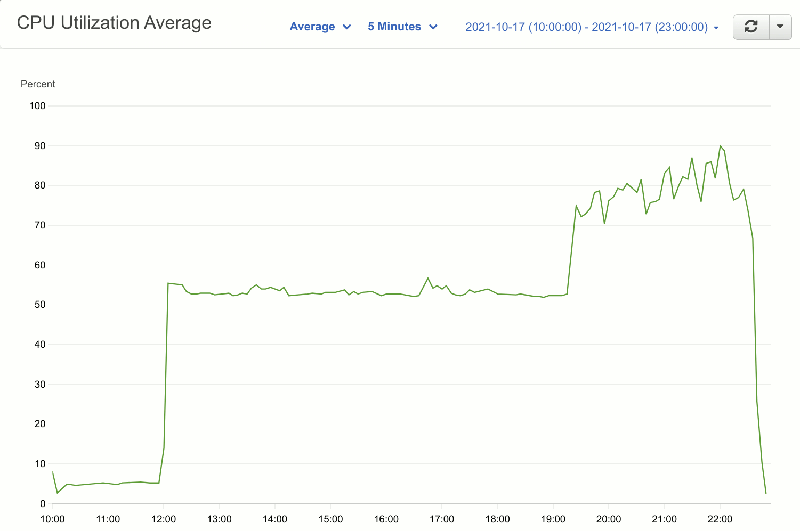
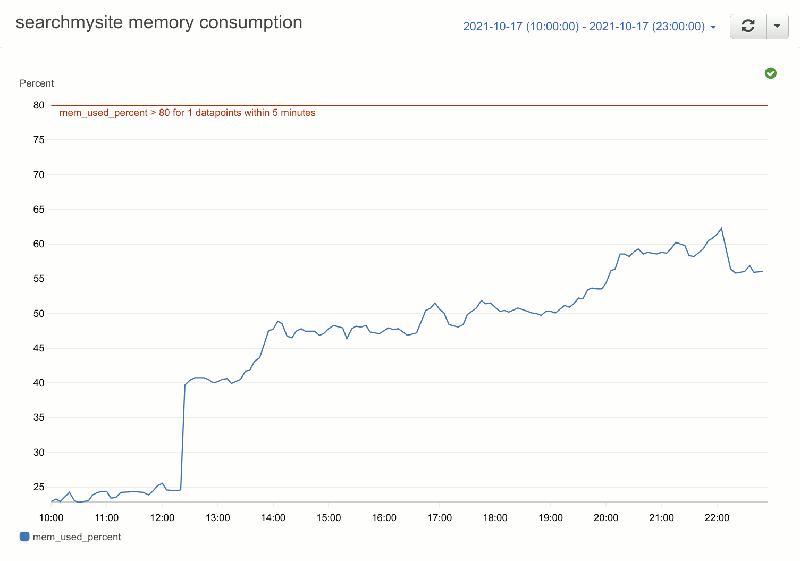
Here’s how CPU and memory usage vaied over the same time:
How long the Wikipedia import takes
Over the years I’ve become accustomed to production processes running faster than development, and thought that would be the case here, especially given my development machine is now nearly 7 years old and wasn’t especially high-spec in the first place. But I was forgetting that we’re now in the cloud era, and that this project is being run on a shoe-string budget (more specifically a t3.medium EC2 instance with 2 vCPUs and 4Gb RAM). So it turns out that it runs more quickly on my dev machine:
| Step | Dev | Prod |
|---|---|---|
| 2 Download | 120 min | 111 min |
| 3 Uncompress | 43 min | 21 min |
| 4 Reformat | 122 min | 418 min |
| 5 Load | 183 min | 196 min |
| Total | 7 hours 48 min | 12 hours 26 min |
Tuning Solr for 6,500,000 documents
As per above, I’m running everything (Apache Solr, Postgres database, web site, indexing processes, self-hosted analytics) on one server with 4Gb RAM. I’d left Solr with the default 0.5Mb, which was fine when the index contained less than 100,000 pages, but wasn’t working so well with over 6,000,000 pages. So I’ve increased Solr’s memory 1Gb for now (with environment: SOLR_JAVA_MEM: "-Xms1024M -Xmx1024M" in the docker-compose.yml). The main user of memory was actually the indexer (at least when it was running) so I’ve decreased the number of sites which can be concurrently indexed from 20 to 16, to compensate for Solr’s increased allocation.
One interesting issue is that the original relevancy tuning became unusably slow when the number of documents increased from under 100,000 to over 6,500,000. It turns out that the culprit was the if(exists(content),1,0.5) clause. I’m not entirely sure if this is due to some missing cache configuration or something on my side, or a bug in Solr, but I’ve removed for now because it wasn’t the most critical part of the relevancy tuning. The other key parts seem fine, so the relevancy formula is now:
<str name="boost">product( sum(1, log(sum(1, product(indexed_inlink_domains_count, 1.8)))), if(contains_adverts,0.5,1), if(owner_verified,1.1,1) )</str>
Solr performance seems okay, but not as zippy as it was, so it is something to monitor closely. Hopefully it won’t need a memory or CPU upgrade.
Cost
As per the comment in the Scheduling section above, the big bad surprise I got is that while it is easy to increase storage on AWS EBS, it is not possible to decrease (without complex workarounds). That means I’m now paying for 250Gb storage while only currently using around 100Gb. Before the Wikipedia import I was only using 60Gb. At US$0.116 (GBP0.084) per Gb, that extra 190Gb is going to cost US$22.04 (GBP15.96) or US$264.48 (GBP191.52) per year.
It is still too early to see the impact on CPU and memory costs, but it is looking likely that that the total cost of running searchmysite.net will breach $1,000 (GBP728) per year, which is starting to get a little on the expensive side for a side-project.
Given running costs have been increasing steadily in the 15 months since launch, and the number of paid listings is still relatively low, this could be a make or break period for the project.
-
I had hoped people would submit interesting sites they’d found via Quick Add and their own sites via Verified Add, but what seems to be happening is that people are simply submitting their own via Quick Add - maybe I need a message on the home page to make it clearer how people can help improve the search for all. ↩︎
-
“The first Google index in 1998 already had 26 million pages” according to https://googleblog.blogspot.com/2008/07/we-knew-web-was-big.html. ↩︎