searchmysite.net: The delicate matter of the bill
Introduction
searchmysite.net is an open source search engine and search as a service for personal and independent websites. The first users began submitting sites on 17 July 2020, and it has been growing steadily since then. It is a bootstrapped side-project, so currently receives no external funding. Furthermore, it does not plan to fund itself with advertising, unlike pretty much every other search engine.
This post contains a quick review of current and expected future running costs, along with a summary of the plan to pay these running costs. The future estimates aren’t necessarily very accurate, and there isn’t much detail on possible cost optimisations, because the main focus is still on building the system, increasing adoption, and of course testing whether the idea of a search engine sustained by anything other than advertising can actually work.
The costs also don’t factor in my time, which at roughly 2 hours a day for 5 days a week over 7 months, plus the week I took off to work on the project full-time (22 June to 26 June 2020), probably come to over 350 hours so far, or roughly 0.25 FTE (Full-Time Equivalent).
For reference, in the very first post announcing the project on 18 Jul, I said I was hoping I’d be able to support 1,000 sites on one t3.medium instance, and to keep running costs to under £300 ($400) a year if on a t3.medium instance.
Current running costs
The actual bills so far have been:
| Month | Cost |
|---|---|
| July 2020 | $9.04 |
| August 2020 | $20.47 |
| September 2020 | $28.95 |
| October 2020 | $41.09 |
| November 2020 | $44.64 |
| December 2020 | $47.13 |
Note that the site wasn’t online for the full month in July, and was running on a t3.micro instance until it was upgraded to a t3.medium instance in September (see also searchmysite.net update: Seeding and scaling).
Here’s the full detail of the most recent bill (December 2020):
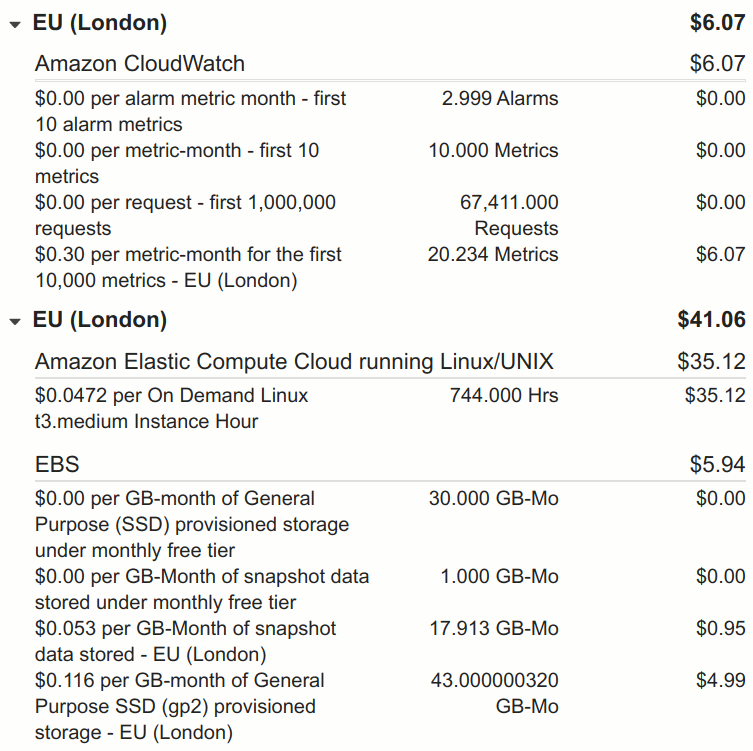
So most of the cost is compute time, i.e. CPU and memory. As noted in Improving stability and fixing issues on searchmysite.net, the indexing process consumes the vast majority of CPU and memory. A large complex site can take over 1 hour to index, creating a noticeable spike in CPU and memory usage, and verified sites are indexed twice a week1.
It therefore makes sense at this stage to think of running costs in terms of a base cost for a particular hardware configuration, plus an incremental cost for each site being indexed. If you compare the monthly bills against the number of sites indexed, and work out the average monthly cost per site, you get the following:
| Month | Cost | No of sites | Cost per site |
|---|---|---|---|
| July 2020 | $9.04 | 10 | $0.90 |
| August 2020 | $20.47 | 11 | $1.86 |
| September 2020 | $28.95 | 442 | $0.07 |
| October 2020 | $41.09 | 685 | $0.06 |
| November 2020 | $44.64 | 720 | $0.06 |
| December 2020 | $47.13 | 742 | $0.06 |
Expected future running costs
Looking at the cost per site, it seems to be settling in to around $0.06 per site per month, or $0.72 per site per year, on a t3.medium instance. That would mean 1,000 sites would cost $720 (£530) a year, which is nearly twice the initial hope of $400 (£300) a year.
Based on current growth, it is likely to reach 1,000 sites sometime between February and July 2021, and by the end of 2021 could be on between 1,500 and 2,000 sites. The end-of-year figure would potentially be $1,080 (£795) to $1,440 (£1,060) a year if it is still on a single t3.medium instance, although it will almost certainly have to be upgraded by then.
Other possible changes which would increase runnings costs include:
- Setup multiple web and indexing servers on production.
- Index wikipedia. If implemented, it would use a bulk import of the biweekly data extracts, rather than the normal spidering process. The main impact of that would be storage and memory. The uncompressed XML files for the English-only wikipedia are currently around 125Gb, so after indexing the total increase in storage requirements could be 250Gb, which would be roughly $30 extra per month. It is unlikely the significantly larger index could operate within the current 4Gb of memory (which is at times 98% utilised), but assuming it could work with 8Gb, that would also be another roughly $30 per month. So it could be around $60 a month extra to add wikipedia searching, or $720 (£530) a year, not factoring in potential data ingress fees.
Of course there are plenty of options for reducing costs, e.g. optimising the indexing code, making indexing less frequent for the basic listings, using a cheaper instance type, using a different pricing model, or even switching cloud provider. But this exercise is just to get a rough idea for now.
The plan to pay running costs
What should be becoming clear is that this is getting pretty expensive for a side-project.
Fortunately, there has always been a plan to try to make the project sustainable (see e.g. What went wrong with the internet (and how can it be fixed)? published before development was even started). The plan is to charge a fee for the verified owner site listings. In return for helping to sustain the service without advertising or a subscription fee, the paid listing would give site owners the following benefits (as laid out on the Quick Add page):
- Significantly more pages indexed.
- Increased indexing frequency.
- The ability to trigger reindexing on demand.
- Access to the API.
- Other indexing configuration, via the Manage Site interface.
I’d quite like to keep the listing fee reasonably low, and was thinking in terms of it being not dissimilar to the annual fee for registering a domain. So I’m starting out at £12 (approx $16 or EUR13) a year for now. That is not too far out of line with other search as a service providers, but note that searchmysite.net is so much more than just another search as a service.
At that price point, assuming the running cost estimates above are correct, I’d need approximately 45 sites to pay the fee for every 1,000 sites listed, i.e. 4.5% verified. At the moment, with no listing fee, approximately 9.5% of sites go through the verification process. So 4.5% might be a little optimistic, but not completely impossible.
It is a difficult decision, but given current and estimated future running costs, and after running for over 6 months, I think it is time to turn on the listing fee now. So let’s see if this can now become a genuinely sustainable alternative advert-free search engine.
-
Compared to the resource utilisation of a standard CRUD (Create, Read, Update and Delete) application, there are a couple of differences: (i) it is fairly resource intensive (involving processor, memory and network heavy processes on a regular on-going basis), and (ii) it uses those resources irrespective of whether anyone is actually using the system or not (most applications would have a direct correlation between server utilisation and popularity/usage). ↩︎